SEO规则
引擎规范
SEO元素
网站内容
Noindex标签在SEO中扮演着重要的角色,尤其是在管理和优化网站内容的索引行为方面。合理和正确地使用Noindex标签可以帮助网站有效地解决重复内容、管理临时页面和保护敏感内容等问题,进而提升整体的搜索引擎排名和用户体验。然而,需要注意的是,过度使用或不正确使用Noindex标签可能会对SEO产生负面影响,因此在使用时应根据具体情况进行谨慎考虑和操作。
正确使用<meta name="robots" content="noindex">标签是非常重要的,它可以指示搜索引擎不要索引特定页面。这在以下情况下特别有用:
1. 防止重复内容被索引
动态生成页面:某些网站可能会动态生成大量内容,如搜索结果页面、标签页面或过滤器页面。这些页面通常没有实际价值,因此可以使用Noindex标签防止它们被索引,从而
避免重复内容问题。
2. 管理测试页面或临时页面
测试页面:在开发或测试新功能时,可能会创建一些临时页面。这些页面通常不希望被搜索引擎索引,以免影响网站的整体SEO表现。通过添加Noindex标签,可以防止这些页面被索引到搜索引擎结果中。
3. 隐藏敏感内容或页面
付费内容:如果网站提供了付费内容或服务,而不希望这些内容被非付费用户访问到,可以使用Noindex标签来确保这些页面不会出现在搜索结果中,保护付费内容的独特性和价值。
如何正确使用Noindex标签:
1、在页面的头部添加标签:

这个标签应该放在页面的<head>部分内。它告诉搜索引擎不要索引这个页面。
2、结合其他标签:
Nofollow标签:如果页面包含外部链接,可以结合使用<meta name="robots" content="nofollow">,以防止搜索引擎跟踪这些链接。
Noarchive标签:<meta name="robots" content="noarchive">可以阻止搜索引擎缓存页面的副本。
3、确认使用场景:
确保在适当的情况下使用Noindex标签。过度使用或不正确使用Noindex标签可能会导致意外的SEO影响,例如排名下降或页面被误认为是低质量内容。
4、验证标签效果:
使用Google Search Console等工具验证Noindex标签的效果。Google Search Console可以显示哪些页面被Noindex,确保其按预期工作。
5、注意事项:
谨慎使用:确保仅在确实需要时才使用Noindex标签,以防止意外排名下降或搜索引擎索引问题。
避免滥用:避免将Noindex标签应用于重要内容或核心页面,这可能导致排名下降或网站流量减少。
规范详细解读:
1、实施 noindex两种方式:将其作为 标记实施,或作为 HTTP 响应标头实施;
2、 标记格式:;
3、返回值为 noindex 或 none 的 X-Robots-Tag HTTP 标头:X-Robots-Tag: noindex;
4、确保 noindex 规则对 Googlebot 可见;
示例:
<meta name="robots" content="noindex, nofollow" />
谷歌官方说明:
noindex 是一个包含 <meta> 标记或 HTTP 响应标头的规则集,用于防止支持 noindex 规则的搜索引擎(例如 Google)将内容编入索引。当 Googlebot 抓取该网页并发现该标记或标头时,Google 就会完全阻止该网页出现在 Google 搜索结果中,不论是否有其他网站链接到该网页。
1、实施 noindex
实施 noindex 的方法有两种:将其作为 <meta> 标记实施,或作为 HTTP 响应标头实施。这两种方法的效果相同,从中选择更方便您网站采用并且更适合相应内容类型的那一种方法即可。Google 不支持在 robots.txt 文件中指定 noindex 规则。
您还可以将 noindex 规则与其他控制索引的规则结合使用。例如,您可以结合使用 nofollow 提示和 noindex 规则: <meta name="robots" content="noindex, nofollow" />。
<meta> 标记
为防止支持 noindex 规则的所有搜索引擎将您网站上的某个网页编入索引,并将以下 <meta> 标记添加到网页的 <head> 部分:

若想仅阻止 Google 网页抓取工具将网页编入索引,请使用以下元标记:

请注意,某些搜索引擎对 noindex 规则可能会有不同的解读。因此,您的网页可能仍会出现在其他搜索引擎的结果中。
2、HTTP 响应标头
您可以在响应中返回值为 noindex 或 none 的 X-Robots-Tag HTTP 标头,而不是 <meta> 标记。 响应标头可用于非 HTML 资源,例如 PDF、视频文件和图片文件。下面是一个 HTTP 响应示例,它含有一个 X-Robots-Tag 标头,用来指示搜索引擎不要将某一网页编入索引:
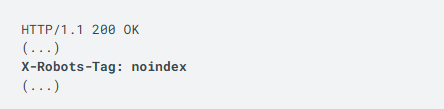
3、调试 noindex 问题
我们必须抓取您的网页,才能看到 <meta> 标记和 HTTP 标头。如果某个网页仍显示在搜索结果中,可能是因为在您添加 noindex 规则后我们尚未抓取过该网页。根据该网页在互联网中的重要性,Googlebot 可能需要数月时间才能重新访问该网页。您可以使用网址检查工具请求 Google 重新抓取您的网页。
此外,也可能是因为 robots.txt 文件阻止 Google 网页抓取工具访问该网址,因此这些抓取工具无法发现此标记。若要允许 Google 访问您的网页,您必须修改 robots.txt 文件。
最后,请确保 noindex 规则对 Googlebot 可见。如需测试您的 noindex 实现是否正确,请使用网址检查工具查看 Googlebot 在抓取该网页时收到的 HTML。 您还可以使用 Search Console 中的“网页索引编制”报告监控您网站上 Googlebot 从中发现 noindex 规则的网页。